

为了充分融合不同深度学习模型在建筑提取中的互补信息,该文提出一种基于深度学习概率决策融合的高分辨率影像建筑物提取方法,将不同深度学习模型的类别分割概率进行融合作为最终建筑提取的依据,以实现不同模型之间的优势互补,最后采用形态学后处理方法进一步优化建筑提取结果。采用3组不同分辨率,具有多种地物形态的建筑数据集验证本文方法的有效性。实验表明该文提出的概率决策融合方法取得了满意的精度(F指数分别为92.45%,90.56%,79.95%),优于单一模型的结果,并且显著提升了建筑提取结果的可靠性。
引言
建筑是城市最主要的地物类型之一,建筑信息的准确提取对城市规划管理、人口密度估计和自然灾害评估等方面具有重要意义[1]。高分辨率影像具有丰富的地物细节信息,能够区分建筑、道路等城市基本地物,为大范围的建筑物提取提供了可能性。过去几十年,高分辨率影像建筑信息提取一直是遥感和计算机视觉领域的热点研究问题,吸引着众多学者的关注[2]。
当前,建筑提取的方法主要包括自动提取方法,传统的监督分类方法和深度学习方法。建筑的自动提取主要采用基于知识和规则的方法,根据建筑物的光谱、纹理、形状、空间关系等基本特征,构建建筑提取的规则[3]。比如建筑与附近的地物之间会形成较高的局部对比度,建筑和阴影存在空间共生关系。基于这些规则,一些学者构建了自动化的建筑指数,如形态学建筑指数(morphological building index, MBI)和建筑区域指数PanTex[2, 4]。监督分类方法依赖于一定人力的样本标记和搜集,由于可以从训练样本中获得先验知识,监督分类方法能够更好地应对复杂场景下的建筑提取。传统的监督分类方法多采用多特征融合的机器学习方法,其关键也是在于设计有效的特征来描述建筑的属性。除了光谱特征之外,空间特征常常被用来弥补高分辨率影像上光谱特征对建筑属性描述的不足。常用的空间特征包括形态学差分谱[5]、灰度共生矩阵[6](gray-level co-occurance matrix, GLCM)等。然而,以上方法主要采用人工设计特征,依赖于专家知识。而且,由于建筑自身和环境的复杂性,人为设计的底层特征在描述建筑属性时,依然存在巨大挑战。
近些年来,基于卷积神经网络(convolutional neural network, CNN)的深度学习方法已经越来越多地应用于计算机视觉和图像处理领域,并且取得了巨大的成功。相对于传统的特征工程方法,深度学习是一种数据驱动的模型,它拥有强大的特征学习和表征能力,能够从标记数据中自动学得中高层的抽象特征[7]。建筑提取在计算机视觉领域可以看成是一个语义分割问题,即对影像上的建筑物与非建筑物进行像素级的类别标记区分。目前,众多典型的CNN模型,如全卷积神经网络(fully convolutional network,FCN)[8]、 Segnet [9]、U-net [10]、 Deeplab系列[11]等,已经成功应用于影像的语义分割任务。其中,基于深度学习的高分辨率影像建筑提取研究,也取得了一定进展。比如:文献[12]采用两步法CNN模型从高分辨率影像上提取乡村的建筑。该方法第一阶段在粗尺度上进行村庄的定位与提取,随后在村庄区域进行精细尺度的单个建筑提取。该方法能够减少影像背景的复杂性,提升乡村建筑的提取效率。文献[13]提出一种基于深度残差网络的模型用于建筑探测,同时采用面向对象的滤波方法进一步优化建筑提取结果。文献[14]采用Deeplab-v3+模型对遥感影像进行了建筑的分割。
CNN模型众多,不同模型的构建方式也不尽相同,针对高分辨率影像上建筑提取这个特定任务,不同的CNN模型可能表现出不同的优势,融合不同深度模型的结果有望进一步优化。因此,本文提出一种基于深度学习概率决策融合的建筑提取方法,在决策层融合不同模型的类别分割概率作为最终类别标记的依据,以期不同的CNN模型能够优势互补,提升建筑提取的精度与置信度,最后根据建筑几何属性,采用后处理操作,进一步优化建筑提取结果。
建筑提取方法
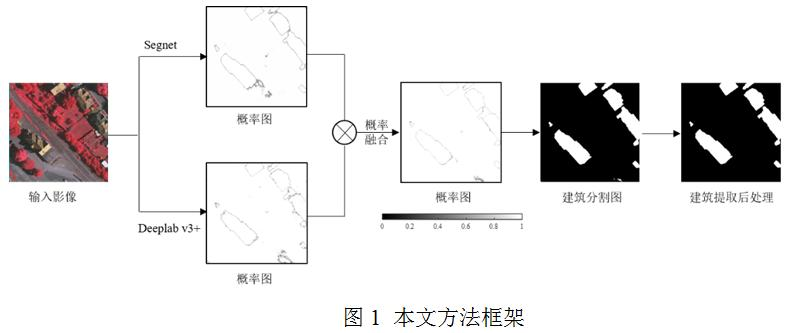
图1展示了本文的方法框架。首先,采用不同的卷积神经网络(本文选取Segnet和Deeplab v3+两个典型网络)对影像进行语义分割,生成类别概率图;然后,在决策层融合不同网络模型的类别概率来实现不同模型的优势互补,提升建筑提取的精度与可靠性;最后,根据建筑物的几何信息,采用必要的后处理操作对建筑提取结果进一步优化得到比较纯净的建筑信息。
文献[15]在2015年提出FCN,实现了基于端到端的CNN图像语义分割。FCN使用卷积层替换CNN中的全连接层,可以接受任意尺寸的输入图像。为了使影像的输出与输入大小相同,FCN将特征图上采样到与输入图像相同的尺寸,同时融合浅层网络学习到的特征,得到更好的分割结果。在FCN的引领下,基于CNN的语义分割方法开始蓬勃发展,出现了Segnet、 U-net、 Deeplab系列等。这些网络实现方式不同,在具体的语义分割任务中,可能有各自的优势。因此,对它们的结果进行融合,有望实现优势互补,进一步优化分割结果。本文将以典型的语义分割网络Segnet和Deeplab v3+为例,探索概率决策融合对高分辨率影像建筑识别的有效性。下面简要介绍Segnet和Deeplab v3+的基本原理。
Segnet
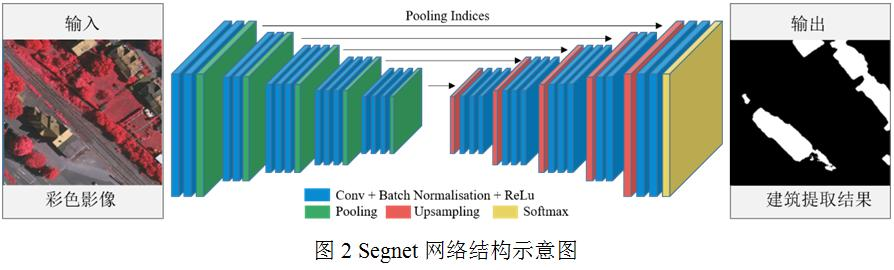
Segnet是一个经典的语义分割网络模型,该模型使用了“编码-解码”的对称结构[8](图2)。其中,编码器是指网络的特征提取部分,使用卷积层和池化层逐渐缩小图像的尺寸,编码器网络结构可采用去除全连接层的VGG-16网络[16]。解码器是指将特征图转化为预测图的部分,使用了一系列的上采样和卷积操作,其结构的关键之处在于解码阶段用到了编码器在池化时的索引值,从而能以原有的信息进行上采样,恢复目标的边缘位置,得到更加准确的分割结果。
Deeplab v3+
Deeplab v3+是Deeplab系列模型的最新版本,自从文献[17]采用空洞卷积算法,提出deeplab v1以来,作者不断推陈出新,探索ResNet[18]和Xception[19]等模型作为不同的特征提取器,引入带孔的空间金字塔模块(atrous spatial pyramid pooling, ASPP)和编码-解码结构[20],对原有模型进行进一步的改进。ASPP包含不同尺度的带孔卷积核对图像进行处理,能够挖掘图像的多尺度和上下文内容信息,提取影像的高层特征。为了防止目标边界信息因为池化和卷积操作而丢失,引入的编码-解码器结构可以通过逐步恢复空间信息来获得更清晰的目标边界。综上,Deeplab v3+通过采用ASPP模块和编码-解码结构,处理多尺度的图像上下文信息,优化分割结果,提高目标的分割精度。2
概率决策融合与置信度
语义分割模型众多,不同的模型实现方式和技巧有着较大的区别,针对一个具体的语义分割任务,不同的网络模型可能拥有各自的优势。因此,本文认为将不同模型进行融合有望实现模型之间的优势互补,从而进一步提升模型的影像分割精度。具体地,本文认为Segnet和Deeplab v3+模型在高分辨率影像建筑识别的任务中,能够提取到互补的信息。考虑到深度学习在预测时不仅能够直接输出类别标签,也能够得到每个像素属于每个类别的概率信息,因此,本文将不同语义分割模型独立输出的类别概率进行决策层的概率融合,根据融合概率确定最终的类别标记结果,以提升建筑提取的精度。概率融合公式表示如下:

需要说明的是,概率决策融合方法可以看成是一种框架,它可以融合不同的语义分割模型,本文只是以Segnet和Deeplab v3+为例,探究模型融合的有效性。
为进一步探究概率融合的效果,本文从分类置信度角度继续分析。对于二类分割任务,分类概率可以直接衡量某个类别的分割置信度,分类概率值越大,表明该像素分类置信度越高。本文统计不同CNN模型以及融合模型中高置信度分类结果的比例,探究概率融合对分类置信度的影响。具体地,本文设置9为高置信度分割结果。初始的建筑提取结果一般会包含细小的噪声、对象孔洞等,影响了建筑提取的精度。根据建筑属性认知,本文采用面积约束和建筑孔洞填充进一步对初始建筑提取结果进行后处理优化。具体地,若某一探测的建筑对象的面积小于给定阈值c,则该对象被标记为背景;若建筑孔洞局部半径小于给定阈值r,则对该孔洞进行形态学重构运算进行填充并且保持该建筑对象的边缘[21]。面积约束能够减少建筑提取的错检误差,建筑孔洞填充能够减少建筑提取的遗漏误差,从而整体上提高建筑检测的精度。考虑到建筑物的几何属性,本实验中,最小建筑的面积阈值c设为5 m2,建筑孔洞局部半径阈值r设为2 m,对应形态学运算的圆形结构元素半径大小。
本文采用准确率(P)、召回率(R)和F指数(F)3个常用的指标来衡量建筑提取的精度。其中,准确率可以衡量建筑提取的正确率,召回率反映建筑提取的完备率,F指数是同时考虑建筑提取准确性与完备性的综合指标。3个指标的定义公式如下:

式中:TP表示正类预测为正类,即正确检测的建筑,FP表示将负类预测为正类,即错误检测的建筑,对应错分误差;FN表示正类预测为负类,即遗漏的建筑,对应漏分误差;表示像素个数。
实验与分析本文采用了3种不同分辨率的建筑数据集进行实验(图3),分别是国际摄影测量与遥感协会(International Society for Photogrammetry and RemoteSensing, ISPRS)的Vaihingen建筑数据集,分辨率0.09 m(http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html),武汉大学季顺平团队生产的建筑数据集(WHU Building),分辨率0.3 m(http://study.rsgis.whu.edu.cn/pages/download/),马萨诸塞州建筑数据集(Massachusetts Building),分辨率1 m(https://www.cs.toronto.edu/~vmnih/data/)。ISPRS Vaihingen数据集包含近红外和红绿共3个波段,一共有33个不同大小的影像区域(尺寸大约在2 500像素×2 500像素左右),其中16个区域为训练影像,其它17个区域为测试影像。WHU Building数据集包含4 736个训练样本块,1 036个验证样本块,2 416个测试样本块,大小都为512像素×512像素。MassachusettsBuilding数据集包含103个训练影像,4个验证影像,10个测试影像,影像大小都为1 500像素×1 500像素。
考虑到电脑内存,在训练阶段,本文将ISPRS Vaihingen的训练集裁剪为500像素×500像素的规则影像块,裁剪步长为100像素,随机选择其中80%的图像块作为训练数据,其余作为验证数据。
Massachusetts Building的数据集和验证集也被裁剪成500×500像素的规则影像块,裁剪步长为200像素。在模型预测阶段,内存消耗相对较少,并且语义分割网络可以接受任意尺寸的图像输入,ISPRS Vaihingen和Massachusetts Building数据集的原始测试影像均可直接输入到训练好的模型中进行预测。表 1和图3展示了具体的数据集信息。
在训练过程中,对训练样本进行了数据增强处理,如平移、翻转等操作。Segnet和Deeplab v3+分别采用预训练的VGG-16 [16]和ResNet-18 [18]作为网络骨架,采用动量梯度随机下降法(stochastic gradient descent with momentum, SGDM)进行训练,本文在实验过程中对CNN的训练参数进行了调试优化,同时也参考现有文献中的参数设置,动量参数设为0.9,初始学习率为0.001,batch size大小为4,训练轮数为100,在训练过程中,每500次迭代做一次精度验证。从网络的中间训练过程(图4)以及最终的测试结果来看,这些CNN模型的网络配置是较优合理的。


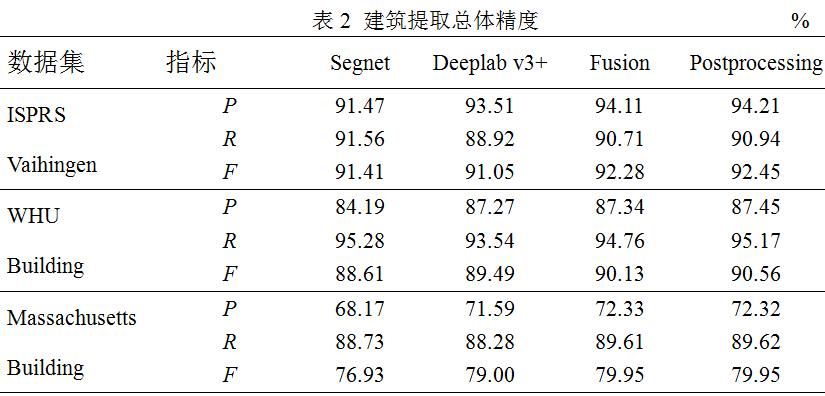
表2展示了建筑提取的精度,可以看到Segnet和Deeplab v3+模型在ISPRS Vaihingen和WHU Building数据集上表现较好,F指数达到了90%左右,在Massachusetts Building数据集上精度相对较低,F指数约为80%。对于ISPRS Vaihingen和WHU Building数据集,影像分辨率非常高,建筑物与其它地物区分比较明显,建筑的边缘比较清晰,而Massachusetts Building数据集,分辨率相对较低,建筑目标比较模糊,和周围地物容易混淆,可能影响建筑提取精度。此外,本文注意到两种CNN模型在P和R 2个指标上互有优势,因此,融合两种模型有望实现优势互补。可以看到,本文提出的概率决策融合方法在F指数上取得了优于单一模型的结果,3个数据集上的精度分别达到了92.28%、90.13%和79.95%。这说明本文提出的概率决策融合模型用于高分辨率影像建筑提取的有效性。在此基础上进行形态学后处理(去噪声、补孔洞)操作,也能够进一步提升建筑提取精度,F指数分别达到了92.45%、90.56%和79.95%。但本文也注意到Massachusetts Building数据集的后处理精度几乎没有变化,这可能是因为在较低分辨率影像上,地物的细节和异质性相对较少,建筑初提取结果中的虚警噪声和建筑内部的孔洞现象较少。这种情况下,采用的形态学后处理方法对该数据影响有限。
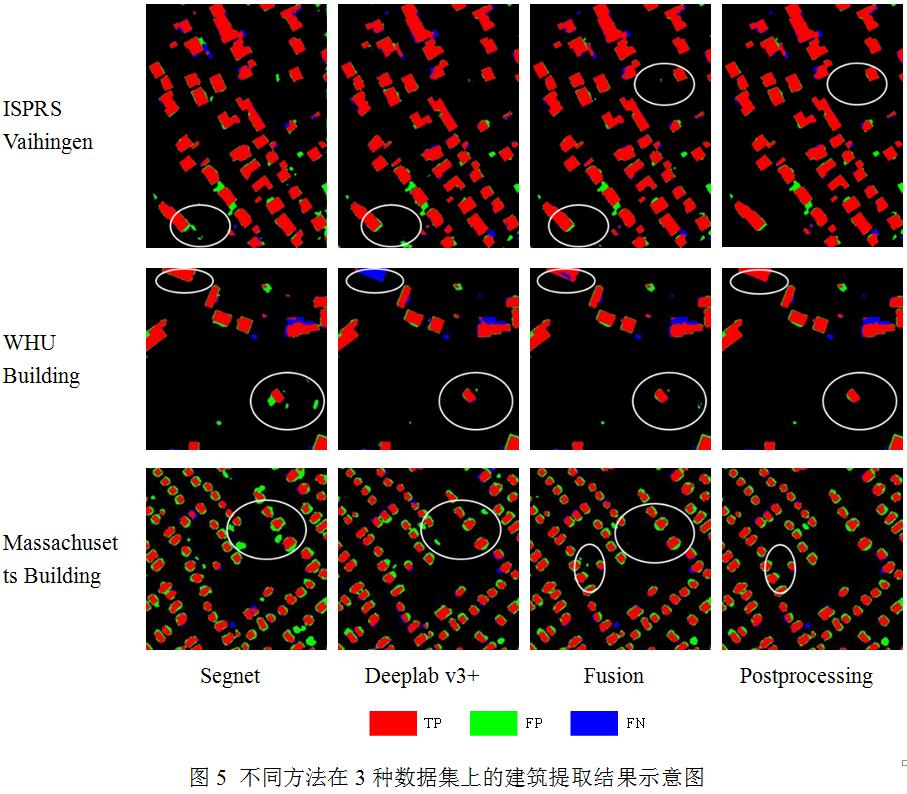
图5展示了建筑提取结果及其精度图,可以看到大部分建筑对象都得到了正确的识别。在ISPRS Vaihingen和Massachusetts Building数据集的标识区域内,Segnet和Deeplab v3+模型在不同地方产生了虚警,但是两者融合后,虚警都被减弱了,并且后处理进一步滤除了细小的噪声,提升了建筑提取的准确率。此外,在WHU Building数据集的标识区域内,Segnet和Deeplab v3+模型分别表现出一些错检和遗漏误差,概率决策融合后,2种误差都得到了缓解,经过后处理,建筑对象内部的小孔洞也被填充,提升了建筑提取的完备率。
综上,本文提出的概率决策融合方法在不同分辨率的数据集上都取得了比单一模型较优的结果。此外,形态学后处理操作能够进一步优化建筑提取结果。考虑到建筑的实际大小和建筑在影像上的可区分能力,并结合本文的实验结果,认为当影像分辨率优于1 m时,比较有利于建筑物的准确提取。
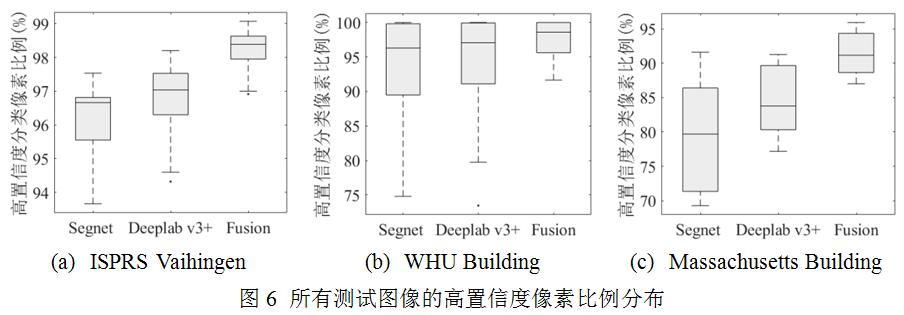
为分析概率决策融合的模型对类别分割置信度的影响,本文统计了每个数据集的所有测试图像在不同模型下的高置信度(分类概率大于0.9)分类像素的比例,并绘制箱型图如图6所示。可以看出来,概率决策融合模型显著提升了分割结果中高置信度像素的比例。比如,在ISPRS Vaihingen数据集中,高置信度像素比例分布的中值由96.6%(Segnet)和97.0%(Deeplab v3+)提升到98.3%(融合模型)。
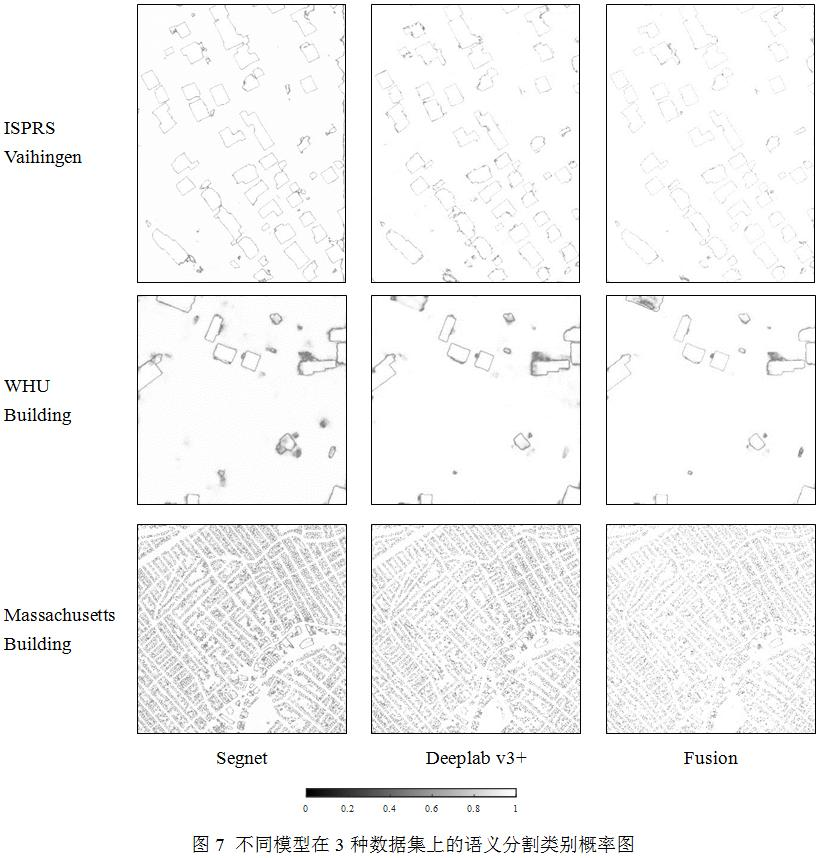
图7展示了不同模型输出的分类置信度图,可以看出来,高置信度的像素主要分布于建筑与背景类别的内部,而置信度较低的像素主要集中在类别间的边界区域,边界区域由于混合了建筑与背景类别的特征,因此分类的可靠性较低。但是,从整体的置信度图目视效果来看,融合模型输出的结果显著提升了类别分割可靠性。
4
典型场景分析本文采用的数据集测试图像众多,图像中地物类型丰富,包括植被、水体、停车场,施工裸地等,有些复杂的场景给建筑提取带来巨大挑战。本文继续分析了本文算法在一些复杂场景下的建筑提取表现。图8(a)展示了ISPRS Vaihingen数据集中的一块测试区域,该区域植被分布较多。本文注意到部分屋顶上也有植被覆盖,这样的建筑很难被检测出来。此外,相邻建筑之间的阴影遮盖也容易造成建筑信息的遗漏。图8(b)展示了WHU Building数据集中的一块施工裸地区域,其中有一些建设区域与建筑特征非常相似,该区域容易造成虚警。图8(c)展示了Massachusetts Building数据集中的一块测试区域,该数据分辨率相对较低,相邻的建筑物之间界限不明显,在检测结果中容易粘连在一起。但也注意到该区域的背景地物如水体与停车场等,本文算法能够将其与建筑较好地区分开来。综上,本文的建筑提取结果在一些复杂场景下也存在一定的错检和遗漏误差,但整体上的表现是合理的。

结束语
高分辨率影像建筑信息提取是遥感领域的研究热点和难点,对城市规划、环境评价具有重要作用。本文提出了一种基于深度学习概率决策融合的高分辨率影像建筑提取方法。该方法在决策层融合不同深度学习模型独立输出的分割概率,实现模型之间的优势互补,并采用形态学后处理操作进一步优化建筑提取结果。实验表明本文提出的方法在多种数据集上取得了满意的精度,优于单一模型的分割结果。而且,概率融合显著提升了类别分割结果的可靠性,降低了分类不确定度。END
引用格式:王珍,张涛,丁乐乐,史芙蓉.高分辨率影像深度学习概率决策融合建筑提取[J].测绘科学,2021,46(6):93-101.
作者简介:王珍,男,内蒙古察右后旗人,正高级工程师,硕士,主要研究方向为工程测量、遥感图像处理与应用
本文链接:https://tuyuangis.com/blog/121.html
本文标签:高分辨率影像
上一篇:2000国家大地坐标系转换指南
下一篇:无人机航测作业流程,你会几个?











